
AI is no longer a side experiment tucked inside an innovation lab. It sits inside core business processes, pricing decisions, hiring pipelines, fraud detection systems, customer service workflows, forecasting models, and executive dashboards. In many organizations, AI outputs are already influencing decisions that move millions of dollars, shape regulatory exposure, and affect real people in real ways.
That shift changes the executive responsibility around AI.
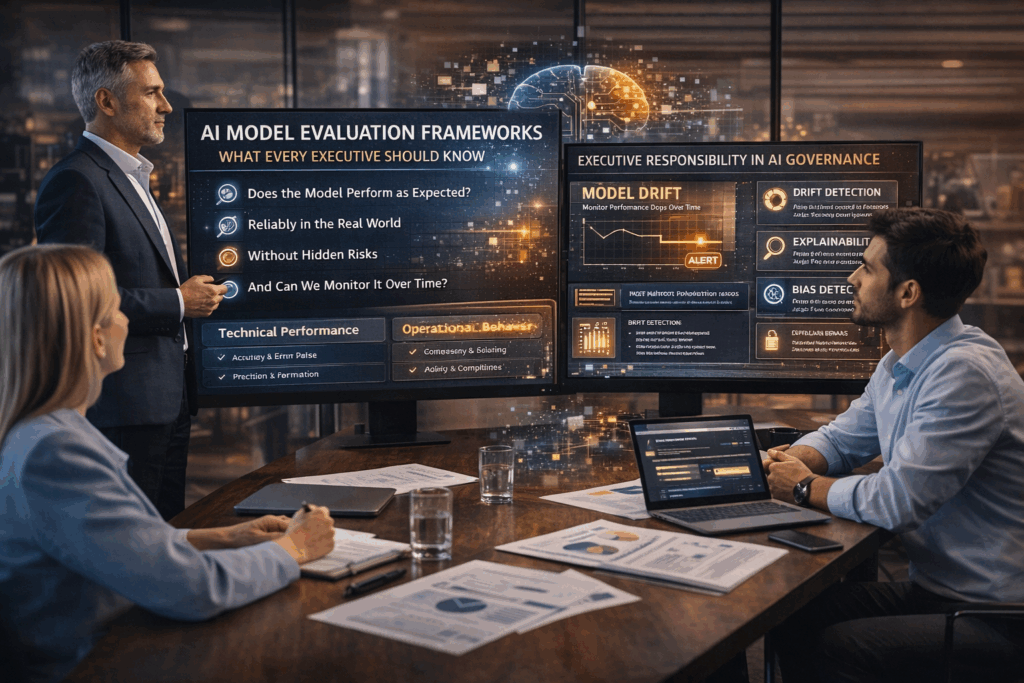
The question is no longer “Does this model work?” The real question is “How do we know it works well enough, safely enough, and consistently enough to trust it at scale?”
This is where AI model evaluation frameworks come in. Not as a technical checklist for data scientists, but as a governance and operating discipline that leadership needs to understand, sponsor, and enforce.
At BizKey Hub, we see AI evaluation as one of the most overlooked risks in enterprise AI adoption. Teams rush to deploy models because the demos look impressive. Performance metrics get mentioned in passing. Then the model quietly drifts, degrades, or starts making decisions no one can explain.
Executives don’t need to become machine learning experts. They do need a working mental model for how AI systems should be evaluated, monitored, and governed over time. This article breaks that down in practical terms, without hype, without jargon overload, and with a clear focus on what leaders actually need to know.
Why AI Model Evaluation Is an Executive Issue, Not a Technical Detail
Most AI failures don’t happen because the math was wrong. They happen because the organization misunderstood what “good performance” actually meant in the context of the business.
A model can score high on accuracy and still cause damage. A system can pass internal tests and still fail in the real world. An AI tool can save time in one department while creating hidden risk in another.
Evaluation frameworks exist to prevent these disconnects.
From an executive perspective, AI model evaluation answers four core questions:
- Does this model perform the task we think it performs?
- Does it behave reliably across real-world scenarios, not just test data?
- Does it introduce legal, ethical, or operational risk we can’t see yet?
- Do we have a way to detect when it stops performing as expected?
If leadership cannot confidently answer those questions, the organization is effectively running blind.
The Limits of Traditional Performance Metrics
Most executives have heard terms like accuracy, precision, recall, and F1 score. These metrics matter, but they are not enough.
Traditional model metrics measure technical correctness against a labeled dataset. Business reality is messier.
Consider a few examples:
- A fraud detection model that flags 98 percent of fraudulent transactions, but falsely blocks thousands of legitimate customers.
- A resume screening model that matches historical hiring patterns but quietly reinforces bias.
- A forecasting model that performs well on average but fails during market volatility, exactly when leadership needs it most.
These systems may look “successful” on paper. They can still fail the business.
An effective evaluation framework expands the lens beyond raw performance into impact, risk, and resilience.
The Three Layers of AI Model Evaluation Executives Should Understand
A useful way to think about AI evaluation is in three layers: technical performance, operational behavior, and business and risk alignment.
1. Technical Performance (The Foundation)
This is where most teams start, and often where they stop.
Technical evaluation asks whether the model produces correct outputs relative to known data. The specifics depend on the model type, but common measures include:
- Accuracy and error rates
- Precision and recall tradeoffs
- Confidence calibration
- Latency and throughput
Executives don’t need to debate metric formulas. They do need to ensure the organization answers two basic questions:
- What metric actually reflects success for this use case?
- And what level of performance is considered acceptable?
Too often, teams optimize for the easiest metric to measure rather than the metric that reflects real-world value.
2. Operational Evaluation (How the Model Behaves in Practice)
Operational evaluation focuses on how the model behaves once it leaves the lab.
This includes:
- Performance consistency across different user groups, geographies, or data sources
- Sensitivity to edge cases and rare events
- Stability over time as inputs change
- Integration behavior with upstream and downstream systems
This layer is where many AI systems quietly break. Data drifts. User behavior shifts. New inputs appear that were never part of training.
An executive-level question to ask here is simple: “How will we know if this model starts behaving differently than expected?”
If the answer is “We’ll notice complaints,” that’s not a framework. That’s a hope.
3. Business, Legal, and Risk Alignment
This is the layer executives own, whether they realize it or not.
Business-aligned evaluation asks:
- Does this model’s output align with policy, regulation, and internal standards?
- Can we explain decisions to regulators, customers, or auditors if required?
- Does the model amplify or reduce risk in critical processes?
- Are the incentives aligned so teams don’t game metrics to look good?
This is where evaluation frameworks intersect with AI governance and compliance, enterprise risk management, and operational risk.
Frameworks like those from the National Institute of Standards and Technology (NIST) and ISO/IEC standardsincreasingly emphasize evaluation as an ongoing obligation, not a one-time certification.
Why One-Time Testing Is Not Enough
A common executive misconception is that AI evaluation happens before deployment, similar to software testing.
AI systems don’t behave like static software. They learn patterns from data, and those patterns change.
Market conditions shift. User behavior evolves. Vendors update upstream tools. Data pipelines get modified.
All of this can degrade a model that once performed well.
This is why modern evaluation frameworks treat AI as a living system that requires continuous measurement, not a box to check before launch.
From a leadership perspective, the key shift is moving from “Did we test it?” to “How do we continuously validate it?”
Model Drift: The Silent Risk Executives Rarely See Coming
Model drift is one of the most common causes of AI failure, and one of the least understood at the executive level.
Drift occurs when the relationship between inputs and outputs changes over time. Sometimes gradually, sometimes suddenly.
There are two main types executives should be aware of:
- Data drift, where the input data no longer looks like the data the model was trained on
- Concept drift, where the underlying patterns or business logic change
A pricing model trained during stable inflation behaves very differently during economic turbulence. A hiring model trained on past resumes may fail as job requirements evolve.
Without active monitoring and evaluation, drift can go unnoticed until damage is already done.
Strong evaluation frameworks include drift detection as a first-class concern, not an afterthought.
Explainability and Transparency Are Part of Evaluation, Not Extras
Executives often hear explainability discussed as a regulatory or ethical requirement. In practice, it is also a business necessity.
When a model influences decisions that affect customers, employees, or financial outcomes, leadership must be able to answer basic questions:
- Why did the system make this recommendation?
- What factors mattered most?
- Under what conditions might it fail?
Explainability doesn’t mean exposing raw code or complex math. It means having a defensible narrative about how the system behaves.
From an evaluation standpoint, this includes:
- Testing whether explanations are stable and consistent
- Validating that explanations align with domain knowledge
- Ensuring explanations are understandable by non-technical stakeholders
If a model cannot be reasonably explained, it should not be making high-stakes decisions.
Bias, Fairness, and Performance Tradeoffs
Bias evaluation is often treated as a moral discussion. For executives, it is also a performance and risk discussion.
All models reflect the data they are trained on. If that data contains imbalance or historical bias, the model will learn it.
Evaluation frameworks should test:
- Performance differences across demographic or operational groups
- Disparate error rates that may indicate unfair outcomes
- Whether fairness constraints materially affect business objectives
There is no universal definition of “fair.” What matters is that leadership understands the tradeoffs being made and approves them intentionally.
Ignoring fairness doesn’t eliminate bias. It just eliminates visibility.
Vendor Models and Black Boxes Still Need Evaluation
Many executives assume evaluation is only relevant for in-house models. In reality, third-party and embedded AI systems often pose greater risk.
If your CRM, ERP, security platform, or HR system includes AI-driven decisions, you are still accountable for the outcomes.
An executive-grade evaluation framework asks vendors questions like:
- What metrics do you use to evaluate model performance?
- How do you monitor drift and degradation?
- Can we audit or validate outputs independently?
- How do you handle updates or retraining?
“Proprietary” is not an acceptable substitute for governance.
Connecting AI Evaluation to Governance and Decision Rights
Evaluation frameworks fail when they live in isolation.
Effective organizations connect evaluation to clear decision rights. Someone owns the model. Someone owns the data. Someone owns the risk.
Executives should ensure there is clarity around:
- Who approves models for production use
- Who sets acceptable performance thresholds
- Who can pause or roll back a model if issues arise
- How evaluation results are reported to leadership
This turns evaluation from a technical report into an operational control.
What Executives Should Ask Before Approving an AI System
Leaders don’t need to ask technical questions. They need to ask the right questions.
A short executive checklist might include:
- What does success look like for this model in business terms?
- How do we measure failure, not just average performance?
- How often will this model be re‑evaluated?
- What signals tell us it’s time to intervene?
- What risks does this system introduce if it performs incorrectly?
If those questions don’t have clear answers, the evaluation framework isn’t ready.
AI Evaluation as a Competitive Advantage
Organizations that treat AI evaluation as a strategic discipline move faster with less risk.
They deploy models with confidence. They catch issues early. They earn trust with regulators, customers, and partners. They avoid the cycle of hype, backlash, and retreat that stalls many AI programs.
At BizKey Hub, we see evaluation frameworks not as friction, but as leverage. They allow executives to scale AI responsibly, align teams around shared standards, and turn experimentation into durable capability.
AI will only become more embedded in how businesses operate. The organizations that win will be the ones that know, at every stage, whether their systems deserve to be trusted.
That starts with evaluation, not as a technical afterthought, but as an executive responsibility.
Click here to learn more about our approach and how it is truly tailored to each company’s needs.